My Journey Building a Semantic Book Recommender: A Humble Look at What I Learned

I am absolutely thrilled to share a project I recently completed: building a powerful semantic book recommendation engine! This entire process was made possible by an absolutely brilliant and thorough tutorial from freeCodeCamp.org. I went from being slightly intimidated by terms like "vector search" to creating a genuinely intelligent system, and I owe a huge debt of gratitude to the course creator for demystifying the process.
This blog post is my personal project retrospective and is completely copyright-free. The methods and concepts discussed are a direct result of the high-quality, free educational content provided by the tutorial (linked at the end).
What I Learned About "Semantic" Search 🤔
Before this, I thought recommendation systems were mostly about keywords. I quickly learned the difference. A semantic recommender goes deeper—it understands the meaning and context of a book.
The core concept I grasped was how to transform book descriptions into vector embeddings [00:00:09], which are mathematical representations of the text. This is what enables the system to find books that are mathematically "close" to a complex query.The tutorial was fantastic at explaining advanced concepts like semantic similarity, Vector search, and zero-shot classification [00:00:36]—ideas that seemed daunting from the outside but were made incredibly approachable.
The Tools I Used 🛠️
I am so grateful for the clear instruction that demonstrated how straightforward working with LLMs can be [00:00:51]. I got my hands dirty with a powerful set of tools and models:
- Python, LangChain, & Chroma: The core infrastructure, making complex tasks like database creation simple [02:13:57].
- Data Source: The project relied on the "7k Books with Metadata" dataset from Kaggle.
- Dataset Link: Kaggle 7k Books with Metadata
- Large Language Models (LLMs): I utilized specific Hugging Face models for different tasks:
- Embedding/Similarity: sentence-transformers/all-mpnet-base-v2
- Zero-Shot Topic Classification: facebook/bart-large-mnli
- Emotional Tone Analysis: j-hartmann/emotion-english-distilroberta-base
My Step-by-Step Learning Process
The course walked me through every necessary step, making the entire development process clear and logical:
- Data Preparation: I started by loading the Kaggle books dataset [00:11:49]. A crucial first lesson was learning how to properly clean and prepare the raw text data before feeding it to the models [00:01:04].
- Building the Vector Database: This was the most satisfying part! I used LangChain and the embedding model to create the vectors and load them into the Chroma database.
- Content Analysis with LLMs: This is where the recommender truly shines. I learned how to use the classification models to find the topic of a book and even determine its emotional tone [00:01:10].
The Moment It All Clicked
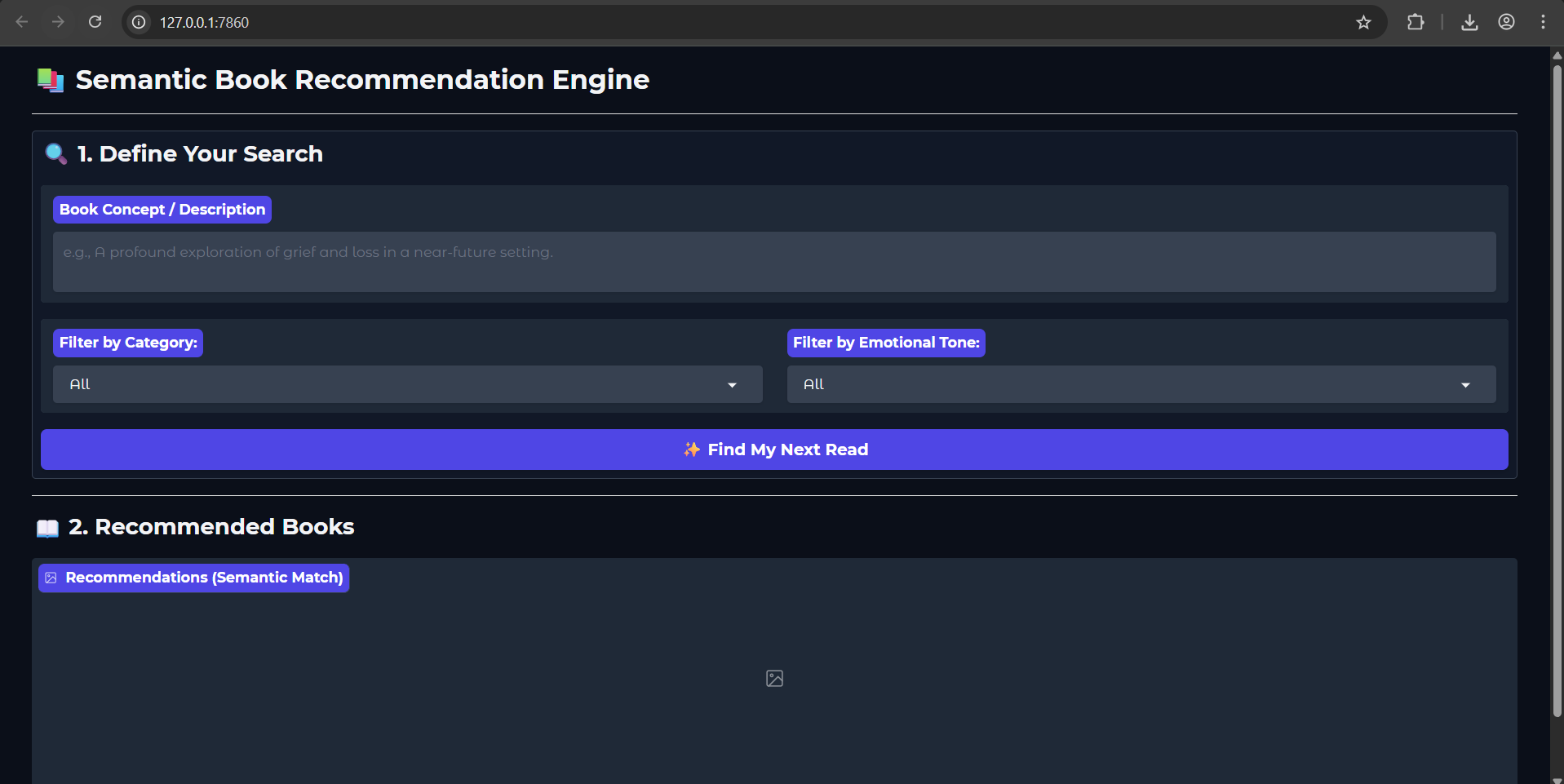
The true validation of what I had learned came when testing the recommender with a nuanced request. I didn't want a simple keyword match; I wanted the system to understand a vibe.
I gave it the challenging query: "a story about a troubled family set across many generations" [02:11:48].
The results were amazing! The recommender, thanks to the methods taught in the tutorial, returned books that matched the requested theme and tone, even if the exact words weren't in the description. I owe all the credit to the clear instruction for helping me build something this sophisticated.
Check Out the Code on GitHub 💻
If you're interested in seeing exactly how I implemented the steps from the tutorial, you can check out my full project code, including the Python scripts for data loading, embedding generation, and the Gradio interface, on my personal repository.
- My Project Repository: richard-pius/A-semantic-library-book-recommender
Watch the Tutorial I Followed (Credit)
I’m feeling incredibly confident and excited about working with LLMs now [02:14:44]. Building this recommender showed me the immense potential of combining vector databases and large language models. A massive thank you to freeCodeCamp.org for providing this incredible, step-by-step resource that made this all possible!
- Tutorial: LLM Course – Build a Semantic Book Recommender (Python, OpenAI, LangChain, Gradio)
- Channel: freeCodeCamp.org
Some Screenshot: